Spark SQL Create Table As Select is your secret weapon for transforming data effortlessly in the big data world. Picture this: you’ve got terabytes of raw data sitting in your data lake, and you need to structure it for analytics. Creating tables on the fly using Spark SQL’s powerful syntax is not just convenient—it’s game-changing. Whether you’re a data engineer, data scientist, or analyst, understanding this feature will supercharge your data processing capabilities.
So, why is Spark SQL Create Table As Select so important? Well, imagine being able to extract, transform, and load data into a structured table with just one command. That’s right—one command! No need to write complex ETL pipelines or worry about intermediate steps. This function simplifies the process, making it faster and more efficient. And let’s face it, who doesn’t love saving time when working with big data?
But hold up! Before we dive deep into the nitty-gritty, let me tell you something cool. Spark SQL Create Table As Select isn’t just about writing queries; it’s about empowering you to manage your data like a pro. From setting up your environment to troubleshooting common issues, this guide will walk you through everything you need to know. Ready to become a Spark SQL wizard? Let’s go!
Read also:Exploring The World Of Subtle Anime Wall Art A Blend Of Style And Serenity
What Exactly is Spark SQL Create Table As Select?
Let’s break it down, shall we? Spark SQL Create Table As Select (often abbreviated as CTAS) is a feature that allows you to create a new table based on the results of a SELECT query. Think of it as a copy-and-paste tool for your data, but way cooler. Instead of manually creating tables and inserting data, Spark SQL CTAS does all the heavy lifting for you. It’s like having a personal assistant for your data management tasks.
Here’s how it works: when you execute a CTAS command, Spark SQL takes the output of your SELECT query and stores it in a new table. This new table automatically inherits the schema of the query result, so you don’t have to define the structure manually. Sounds pretty sweet, right? Plus, CTAS supports various storage formats, so you can choose the one that best fits your use case.
Why Should You Use Spark SQL Create Table As Select?
Now that you know what Spark SQL CTAS is, let’s talk about why you should use it. First and foremost, it simplifies your workflow. Instead of writing multiple queries to create and populate a table, you can do it all in one step. This not only saves time but also reduces the risk of errors. And let’s be honest, fewer errors mean happier developers and analysts.
Another advantage is scalability. Spark SQL CTAS is designed to handle large datasets with ease. Whether you’re working with gigabytes or petabytes of data, Spark SQL can process it efficiently. This makes it an ideal solution for big data projects where performance is critical. Plus, it integrates seamlessly with other Spark components, giving you a unified platform for data processing.
Setting Up Your Spark SQL Environment
Before you can start using Spark SQL CTAS, you need to set up your environment. Don’t worry; it’s not as complicated as it sounds. First, make sure you have Apache Spark installed on your system. You can download it from the official website or use a package manager like Homebrew if you’re on a Mac. Once Spark is installed, you’ll need to configure it to work with your data sources.
Next, fire up your Spark shell or Jupyter notebook and import the necessary libraries. For example, if you’re working with Hive tables, you’ll need to enable Hive support in Spark. This can be done by setting the `spark.sql.catalogImplementation` property to `hive`. Trust me, getting this step right will save you a lot of headaches later on.
Read also:Thomasville Couch Cover The Ultimate Guide To Protecting And Enhancing Your Sofa
Key Configuration Tips
Here are a few tips to help you set up your Spark SQL environment:
- Set the correct storage format for your tables (e.g., Parquet, ORC).
- Adjust the shuffle partitions to optimize performance.
- Enable caching for frequently accessed data.
Remember, the key to a successful Spark SQL setup is fine-tuning these configurations to match your workload. It’s like tuning a guitar—get it right, and everything sounds amazing.
Creating Your First Table with Spark SQL CTAS
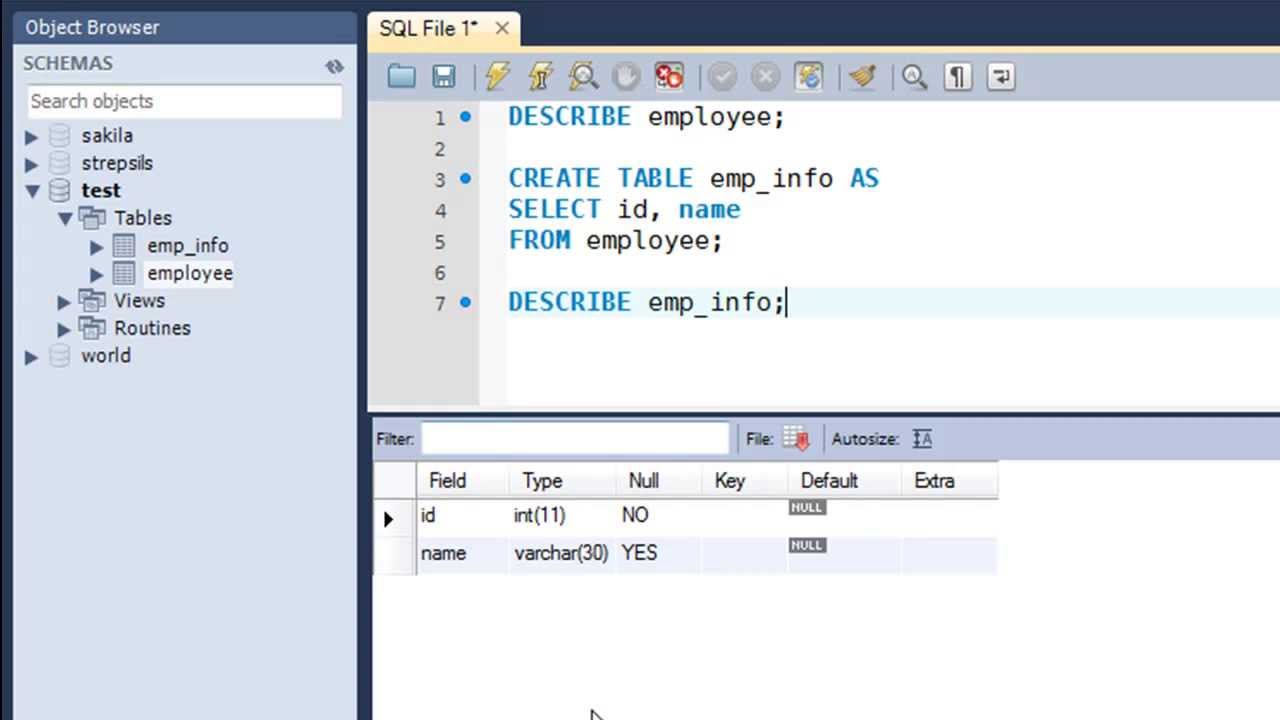
Alright, let’s get our hands dirty! To create your first table using Spark SQL CTAS, you’ll need to write a simple query. Here’s an example:
CREATE TABLE new_table AS SELECT column1, column2 FROM source_table WHERE condition;
Let’s break this down:
- `CREATE TABLE`: This tells Spark SQL to create a new table.
- `new_table`: This is the name of your new table.
- `AS SELECT`: This specifies that the table will be created based on the results of a SELECT query.
- `column1, column2`: These are the columns you want to include in your new table.
- `source_table`: This is the table you’re querying data from.
- `WHERE condition`: This is an optional clause that filters the data.
See? It’s not rocket science. With just one line of code, you’ve created a new table. Now wasn’t that easy?
Handling Complex Queries
Of course, real-world scenarios are rarely this simple. What if you need to perform more complex transformations? No problem! Spark SQL CTAS supports all the usual SQL operations, including JOINs, aggregations, and window functions. For example:
CREATE TABLE aggregated_data AS SELECT department, COUNT(*) AS employee_count FROM employees GROUP BY department;
In this query, we’re creating a table that shows the number of employees in each department. Pretty neat, huh?
Choosing the Right Storage Format
When using Spark SQL CTAS, you have the option to choose the storage format for your new table. This is an important decision because it affects both performance and compatibility. Some popular formats include:
- Parquet: A columnar storage format that’s great for analytical queries.
- ORC: Another columnar format optimized for read-heavy workloads.
- JSON: A human-readable format that’s easy to work with but less efficient for large datasets.
So, how do you choose the right format? It depends on your use case. If you’re running complex queries on large datasets, Parquet or ORC is probably your best bet. But if you need to share data with non-technical users, JSON might be more appropriate. Experiment with different formats to see what works best for your situation.
Best Practices for Storage Formats
Here are a few best practices to keep in mind:
- Use compression to reduce storage requirements.
- Partition your data to improve query performance.
- Regularly clean up old data to free up space.
Following these guidelines will help you get the most out of your chosen storage format.
Managing Table Metadata
Once you’ve created a table using Spark SQL CTAS, it’s important to manage its metadata properly. Metadata includes information like table name, schema, and storage location. Proper metadata management ensures that your tables are easy to find and understand.
One way to manage metadata is by using a metastore. A metastore is a centralized repository that stores metadata for all your Spark SQL tables. By default, Spark uses an embedded metastore, but you can configure it to use an external database like MySQL or PostgreSQL. This is especially useful for large-scale deployments where multiple users need access to the same metadata.
Updating Metadata
Sometimes you’ll need to update the metadata for your tables. For example, you might want to rename a table or change its storage location. Spark SQL provides commands for these operations, such as:
- `ALTER TABLE`: Use this to modify table properties.
- `DROP TABLE`: Use this to delete a table.
Remember, metadata management is an ongoing process. Regularly review your tables to ensure they’re still relevant and up-to-date.
Optimizing Query Performance
Now that you know how to create tables using Spark SQL CTAS, let’s talk about performance. After all, what good is a fast query if it takes forever to execute? There are several strategies you can use to optimize query performance:
- Partitioning: Divide your data into smaller chunks based on a specific column.
- Bucketing: Group related data together for faster joins.
- Caching: Store frequently accessed data in memory for quicker access.
Implementing these strategies can significantly improve the speed of your queries. Just remember, optimization is a balancing act. You’ll need to weigh the benefits against the added complexity.
Common Performance Pitfalls
Here are a few common pitfalls to watch out for:
- Using too many small files, which can slow down processing.
- Not tuning your Spark configuration for your workload.
- Ignoring data skew, which can lead to uneven processing times.
Avoiding these pitfalls will help you achieve optimal performance.
Troubleshooting Common Issues
Even with the best planning, issues can arise. Let’s look at some common problems and how to solve them:
- Query Errors: Double-check your syntax and ensure all tables and columns exist.
- Performance Bottlenecks: Use Spark’s built-in monitoring tools to identify slow stages.
- Metadata Conflicts: Ensure all users have the correct permissions and are using the same metastore.
By addressing these issues promptly, you can keep your Spark SQL environment running smoothly.
When to Seek Help
If you’re stuck on a problem, don’t hesitate to seek help. The Spark community is full of knowledgeable people who are happy to assist. You can find them on forums like Stack Overflow or the Apache Spark mailing list. Sometimes, a fresh pair of eyes is all it takes to solve a tricky issue.
Real-World Use Cases
Let’s explore some real-world use cases for Spark SQL Create Table As Select:
- Data Warehousing: Create summary tables for reporting and analytics.
- ETL Pipelines: Transform raw data into a format suitable for downstream processing.
- Machine Learning: Prepare datasets for training and testing models.
These use cases demonstrate the versatility of Spark SQL CTAS. No matter what your data processing needs are, this feature has got you covered.
Success Stories
Many organizations have successfully implemented Spark SQL CTAS to streamline their data pipelines. For example, a leading e-commerce company uses it to generate daily sales reports, while a financial services firm relies on it for fraud detection. These success stories highlight the value of Spark SQL CTAS in solving real-world problems.
Conclusion: Embrace the Power of Spark SQL Create Table As Select
And there you have it—everything you need to know about Spark SQL Create Table As Select. From setting up your environment to optimizing query performance, this guide has covered it all. Remember, mastering Spark SQL CTAS isn’t just about learning the syntax; it’s about understanding how to apply it to solve real-world problems.
So, what’s next? Start experimenting with Spark SQL CTAS in your own projects. Try out different storage formats, optimize your queries, and explore the many use cases. And don’t forget to share your experiences with the community. Who knows? You might just inspire someone else to take their data processing game to the next level.
Until next time, happy coding!
Table of Contents