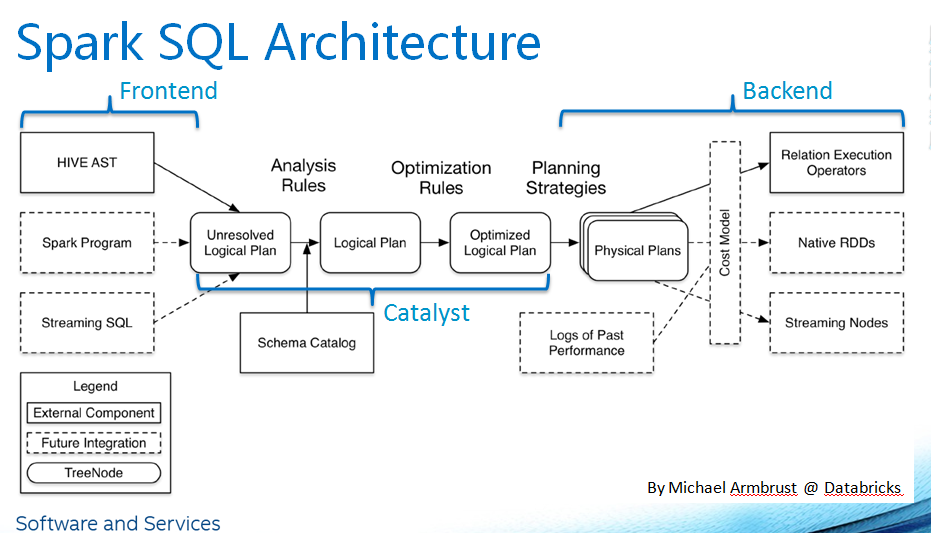
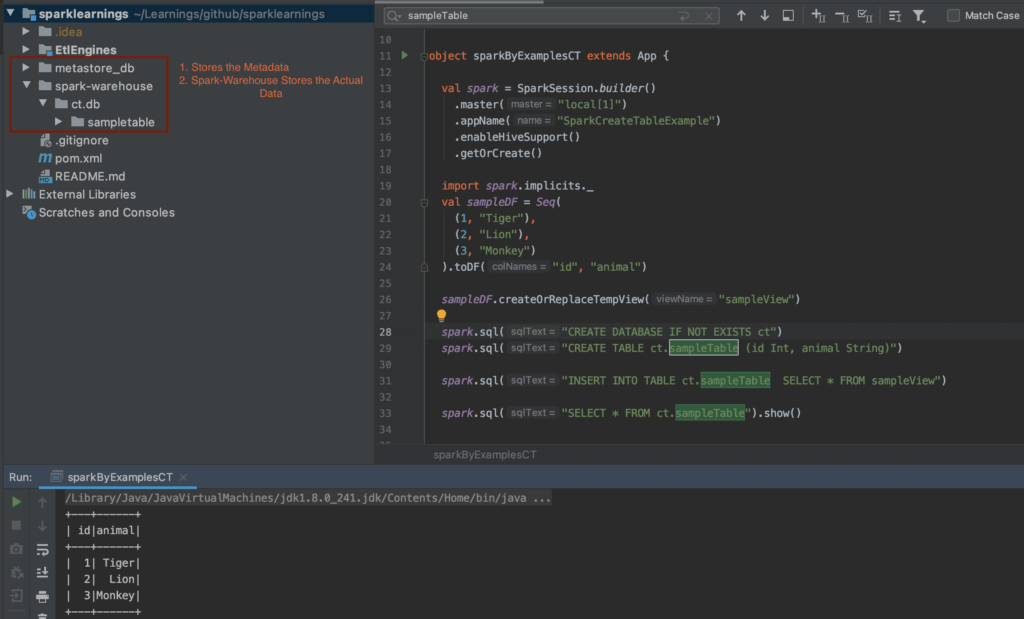
Welcome to the world of Spark SQL tables! If you're diving into the realm of big data processing, you've probably heard about Apache Spark and its powerful SQL capabilities. Spark SQL tables are at the heart of this ecosystem, enabling efficient data management, querying, and analysis. Whether you're a data scientist, engineer, or analyst, understanding Spark SQL tables is essential for optimizing your workflows and unlocking the full potential of your data.
In today's data-driven world, managing massive datasets efficiently has become a challenge for businesses and individuals alike. Apache Spark, with its distributed computing capabilities, has emerged as a game-changer. Spark SQL tables play a crucial role in this process, offering a seamless way to handle structured and semi-structured data. Let's explore why Spark SQL tables are indispensable for anyone working with big data.
This article will take you on a deep dive into the world of Spark SQL tables. We'll cover everything from the basics to advanced concepts, ensuring you gain a comprehensive understanding of how to leverage Spark SQL tables effectively. So, whether you're just starting or looking to enhance your skills, this guide has got you covered.
Read also:Discovering Woo Dohwan Biography Career And Influence
What Are Spark SQL Tables?
Let's break it down. Spark SQL tables are essentially data structures that allow you to store, query, and manipulate data using SQL syntax within the Apache Spark framework. These tables can be temporary or permanent, and they support various data formats such as Parquet, ORC, JSON, and CSV. With Spark SQL tables, you can perform complex operations like filtering, joining, and aggregating data effortlessly.
One of the key advantages of Spark SQL tables is their ability to integrate seamlessly with Spark's core functionalities. This means you can leverage Spark's distributed processing power to handle large-scale datasets efficiently. Moreover, Spark SQL tables provide a unified interface for working with both batch and real-time data, making them versatile for a wide range of applications.
Here’s a quick summary of what Spark SQL tables offer:
- Support for structured and semi-structured data formats.
- Efficient querying using SQL syntax.
- Integration with Spark's distributed computing capabilities.
- Flexibility to handle batch and real-time data processing.
Why Are Spark SQL Tables Important?
In the era of big data, the ability to process and analyze large volumes of information quickly and accurately is crucial. Spark SQL tables address this need by providing a robust framework for data management and analysis. They enable businesses to make data-driven decisions faster and more effectively, which can lead to significant competitive advantages.
For instance, imagine a retail company that collects customer transaction data from multiple sources. By using Spark SQL tables, the company can consolidate this data into a centralized repository, perform complex queries to identify trends, and generate actionable insights. This capability is invaluable for optimizing inventory management, personalizing marketing strategies, and improving overall customer experience.
Additionally, Spark SQL tables are designed to handle the challenges of big data, such as scalability, performance, and fault tolerance. These features ensure that your data processing workflows remain reliable and efficient, even as your datasets grow in size and complexity.
Read also:How Tall Is Ben Affleck Exploring The Actors Height And More
Key Features of Spark SQL Tables
Now that we understand the importance of Spark SQL tables, let's explore some of their key features:
- Data Formats: Spark SQL tables support a wide range of data formats, including Parquet, ORC, JSON, and CSV. This flexibility allows you to work with diverse datasets without worrying about compatibility issues.
- SQL Integration: With Spark SQL tables, you can use familiar SQL syntax to query and manipulate data. This makes it easier for SQL users to transition to Spark and leverage its advanced capabilities.
- Performance Optimization: Spark SQL tables employ advanced techniques like query optimization and caching to ensure high-performance data processing.
- Scalability: Spark SQL tables are built to handle large-scale datasets, making them ideal for big data applications.
How to Create Spark SQL Tables
Creating Spark SQL tables is a straightforward process. You can create tables using SQL commands or programmatically using Spark's API. Below are the steps to create a Spark SQL table:
1. Start by initializing a SparkSession. This is the entry point for working with Spark SQL tables.
2. Load your data into a DataFrame. You can do this by reading from a file, a database, or any other supported data source.
3. Register the DataFrame as a temporary or permanent table. Temporary tables are session-specific, while permanent tables are stored in a metastore.
Here's an example of creating a temporary table:
scala val spark = SparkSession.builder().appName("SparkSQLTableExample").getOrCreate() val df = spark.read.format("csv").option("header", "true").load("data.csv") df.createOrReplaceTempView("myTable")
And here's how to create a permanent table:
scala spark.sql("CREATE TABLE myPermanentTable USING parquet AS SELECT * FROM myTable")
Choosing Between Temporary and Permanent Tables
When deciding whether to use a temporary or permanent table, consider the following factors:
- Temporary Tables: Ideal for short-lived workflows or testing purposes. They are session-specific and do not persist beyond the session.
- Permanent Tables: Suitable for long-term data storage and analysis. They are stored in a metastore and can be accessed across multiple sessions.
Querying Spark SQL Tables
Once you've created a Spark SQL table, you can start querying it using SQL syntax. Spark SQL supports a wide range of SQL operations, including SELECT, WHERE, JOIN, and AGGREGATE. Here's an example of a simple query:
sql SELECT column1, column2 FROM myTable WHERE condition
In addition to basic queries, Spark SQL tables also support advanced features like window functions, subqueries, and Common Table Expressions (CTEs). These features allow you to perform complex data transformations and analyses with ease.
Best Practices for Querying Spark SQL Tables
To optimize your queries and improve performance, follow these best practices:
- Use Indexes: While Spark does not support traditional database indexes, you can optimize queries by partitioning and bucketing your data.
- Limit Data Retrieval: Avoid retrieving unnecessary columns or rows. Use SELECT statements to specify only the required fields.
- Cache Frequently Accessed Data: Caching can significantly improve performance for frequently accessed tables.
Managing Spark SQL Tables
Managing Spark SQL tables involves tasks like updating, deleting, and maintaining data. Spark provides several functions and commands to help you manage your tables effectively. For instance, you can use the ALTER TABLE command to modify table properties or the DROP TABLE command to delete a table.
Here's an example of updating a table:
sql ALTER TABLE myTable ADD COLUMNS (newColumn STRING)
And here's how to delete a table:
sql DROP TABLE myTable
Data Quality and Consistency
Maintaining data quality and consistency is critical when working with Spark SQL tables. You can enforce constraints and validations to ensure that your data meets the required standards. Additionally, regularly auditing your tables can help identify and resolve any data quality issues.
Advanced Topics in Spark SQL Tables
As you become more proficient with Spark SQL tables, you can explore advanced topics like data partitioning, bucketing, and optimization techniques. These features can significantly enhance the performance and scalability of your data processing workflows.
Data Partitioning
Data partitioning involves dividing your data into smaller subsets based on specific criteria, such as date or region. This technique can improve query performance by reducing the amount of data that needs to be scanned.
Data Bucketing
Data bucketing is similar to partitioning but focuses on distributing data across buckets based on a hash function. This approach can improve join performance by ensuring that related data is stored together.
Real-World Applications of Spark SQL Tables
Spark SQL tables are widely used across various industries for a range of applications. Here are a few examples:
- Finance: Banks and financial institutions use Spark SQL tables to analyze transaction data and detect fraudulent activities.
- Retail: Retail companies leverage Spark SQL tables to analyze customer behavior and optimize inventory management.
- Healthcare: Healthcare providers use Spark SQL tables to process and analyze medical records, enabling better patient care and treatment outcomes.
Challenges and Solutions
While Spark SQL tables offer numerous benefits, they also come with their own set of challenges. Some common challenges include:
- Data Skew: Uneven distribution of data can lead to performance issues. This can be mitigated by using techniques like salting or re-partitioning.
- Memory Management: Large datasets can consume significant memory resources. Proper memory tuning and caching strategies can help address this issue.
Conclusion
In conclusion, Spark SQL tables are a powerful tool for managing and analyzing large-scale datasets. By understanding their features, capabilities, and best practices, you can unlock their full potential and enhance your data processing workflows. Whether you're working in finance, retail, healthcare, or any other industry, Spark SQL tables can help you make data-driven decisions faster and more effectively.
We encourage you to experiment with Spark SQL tables and explore the possibilities they offer. Don't hesitate to share your experiences and insights in the comments below. And if you found this article helpful, feel free to share it with your network. Happy data processing!
Table of Contents