Hey there, data wizards and aspiring data enthusiasts! If you're diving headfirst into the world of big data and analytics, then you're probably already aware that Spark SQL is the secret sauce that makes data manipulation faster and easier. But let’s face it, knowing how to create table in Spark SQL isn’t just a skill—it’s a superpower. In this article, we’ll unravel the mysteries of creating tables in Spark SQL, so you can wield this power like a pro. So, buckle up and let’s get started!
Creating tables in Spark SQL might sound intimidating at first, but trust me, it's not as scary as it seems. With the right guidance, you’ll be crafting tables in no time. Whether you're a seasoned developer or just starting out, this guide will walk you through everything you need to know about creating tables in Spark SQL. So, why wait? Let’s dive right in!
Before we jump into the nitty-gritty, let’s take a moment to appreciate the importance of Spark SQL. It’s like having a Swiss Army knife for data processing. With Spark SQL, you can effortlessly handle large datasets and perform complex queries. And when it comes to creating tables, Spark SQL offers a variety of methods that cater to different use cases. So, whether you're working with structured or semi-structured data, Spark SQL has got your back.
Read also:Names Of The Game Of Thrones Dragons A Complete Guide To The Mythical Creatures
Understanding Spark SQL and Why It Matters
Let’s kick things off by understanding what Spark SQL is all about. Spark SQL is an Apache Spark module that allows you to work with structured and semi-structured data. It’s like SQL on steroids, providing powerful features that make data processing a breeze. One of the coolest things about Spark SQL is its ability to seamlessly integrate with other Spark components, making it a versatile tool for big data processing.
Now, why should you care about creating table in Spark SQL? Well, tables are the building blocks of any data-driven application. They help you organize and structure your data, making it easier to analyze and query. With Spark SQL, you can create tables from various data sources, such as CSV files, JSON files, and even databases. This flexibility allows you to work with different types of data and extract valuable insights.
Prerequisites for Creating Tables in Spark SQL
Before you start creating tables, there are a few things you need to have in place. First, you’ll need to have Apache Spark installed on your system. Don’t worry if you’re not sure how to do that—there are plenty of tutorials out there that can guide you through the process. Once you have Spark up and running, you’ll need to set up a SparkSession, which is the entry point for Spark SQL.
Setting up a SparkSession is as easy as pie. All you need to do is import the necessary libraries and create a SparkSession object. This object will serve as your gateway to the world of Spark SQL. With your SparkSession ready, you’ll be able to execute SQL queries and create tables with ease.
Key Components of Spark SQL
Now that you have your SparkSession ready, let’s talk about the key components of Spark SQL that you’ll need to know when creating tables. The first component is the DataFrame, which is a distributed collection of data organized into named columns. Think of it as a table in a relational database. DataFrames are immutable, meaning once you create one, you can’t modify it.
Another important component is the Dataset, which is a strongly-typed version of a DataFrame. Datasets allow you to work with typed objects, making your code more robust and error-resistant. Lastly, we have the Catalyst optimizer, which is Spark SQL’s query optimizer. It analyzes your queries and generates an optimized execution plan, ensuring that your queries run as efficiently as possible.
Read also:Mastering The Art Of How To Apply A Primer A Stepbystep Guide
Methods for Creating Tables in Spark SQL
When it comes to creating tables in Spark SQL, you have several options to choose from. The method you choose will depend on your specific use case and the type of data you’re working with. Let’s take a look at some of the most common methods:
- Using CREATE TABLE Statement: This is the most straightforward method for creating tables in Spark SQL. You simply write a CREATE TABLE statement, specifying the table name, column names, and data types.
- Using DataFrame API: If you’re working with DataFrames, you can easily create a table by registering the DataFrame as a temporary view. This allows you to query the DataFrame using SQL.
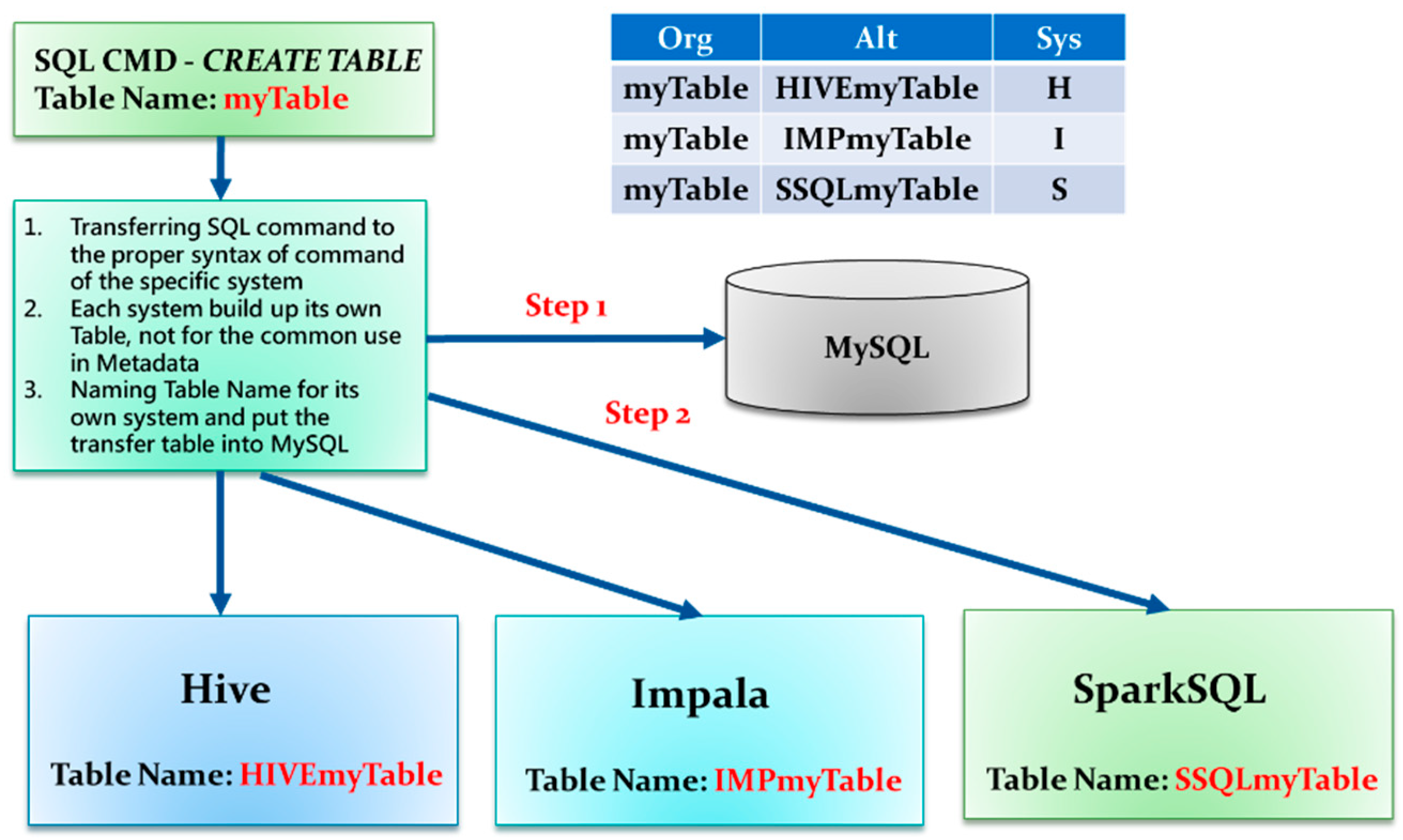
- Using Hive Metastore: If you’re using Spark with Hive, you can create tables in the Hive Metastore. This allows you to persist your tables across Spark sessions.
Each of these methods has its own advantages and disadvantages, so it’s important to choose the one that best fits your needs.
Creating Tables with CREATE TABLE Statement
Let’s dive deeper into creating tables using the CREATE TABLE statement. This method is perfect when you want to create a table from scratch. Here’s an example:
CREATE TABLE employees (id INT, name STRING, salary DOUBLE);
In this example, we’re creating a table called employees with three columns: id, name, and salary. The id column is of type INT, the name column is of type STRING, and the salary column is of type DOUBLE. Simple, right?
Working with External Data Sources
One of the coolest things about Spark SQL is its ability to work with external data sources. Whether you’re dealing with CSV files, JSON files, or databases, Spark SQL has got you covered. Let’s take a look at how you can create tables from external data sources.
To create a table from a CSV file, you’ll need to specify the file path and the schema. Here’s an example:
CREATE TABLE employees USING csv OPTIONS (path "/path/to/employees.csv", header "true");
In this example, we’re creating a table called employees from a CSV file located at /path/to/employees.csv. We’re also specifying that the file has a header row, which makes it easier to map the columns.
Creating Tables from JSON Files
Creating tables from JSON files is just as easy. Here’s an example:
CREATE TABLE employees USING json OPTIONS (path "/path/to/employees.json");
In this example, we’re creating a table called employees from a JSON file located at /path/to/employees.json. Spark SQL will automatically infer the schema from the JSON file, saving you the hassle of defining it manually.
Managing Table Metadata
Once you’ve created your tables, it’s important to manage their metadata properly. Metadata includes information such as table names, column names, data types, and storage locations. Proper metadata management ensures that your tables are easy to query and maintain.
Spark SQL provides several commands for managing table metadata. For example, you can use the DESCRIBE TABLE command to view the structure of a table. You can also use the SHOW TABLES command to list all the tables in your database.
Partitioning and Bucketing Tables
Partitioning and bucketing are two powerful techniques for optimizing table performance in Spark SQL. Partitioning involves dividing a table into smaller partitions based on certain columns. This can significantly improve query performance, especially for large tables.
Bucketing, on the other hand, involves grouping rows with the same value into the same file. This can improve join performance by reducing the amount of data that needs to be shuffled across the network.
Best Practices for Creating Tables in Spark SQL
Now that you know how to create tables in Spark SQL, let’s talk about some best practices to keep in mind. First and foremost, always define your schemas explicitly. This ensures that your data is properly structured and reduces the risk of errors.
Another best practice is to use partitioning and bucketing wherever possible. These techniques can significantly improve query performance, especially for large datasets. Lastly, don’t forget to test your queries thoroughly. This will help you catch any issues early on and ensure that your tables are functioning as expected.
Troubleshooting Common Issues
Even the best-laid plans can go awry sometimes. If you encounter issues while creating tables in Spark SQL, don’t panic. Here are some common issues and how to troubleshoot them:
- Schema Mismatch: If your data doesn’t match the schema you defined, Spark SQL will throw an error. To fix this, double-check your schema and ensure that it matches your data.
- Performance Issues: If your queries are running slowly, consider using partitioning or bucketing to optimize performance.
- Metadata Issues: If you’re having trouble with table metadata, use the DESCRIBE TABLE and SHOW TABLES commands to debug the issue.
Conclusion: Unlocking the Power of Spark SQL
And there you have it, folks! You now know everything you need to create table in Spark SQL like a pro. From understanding the basics of Spark SQL to mastering the art of creating tables, you’ve got the skills to tackle any data processing challenge that comes your way.
So, what are you waiting for? Go ahead and start creating tables in Spark SQL. And don’t forget to share your experience in the comments below. We’d love to hear how you’re using Spark SQL to unlock the power of your data.
Until next time, keep crunching those numbers and stay data-smart!
Table of Contents
- Understanding Spark SQL and Why It Matters
- Prerequisites for Creating Tables in Spark SQL
- Key Components of Spark SQL
- Methods for Creating Tables in Spark SQL
- Creating Tables with CREATE TABLE Statement
- Working with External Data Sources
- Creating Tables from JSON Files
- Managing Table Metadata
- Partitioning and Bucketing Tables
- Best Practices for Creating Tables in Spark SQL
- Troubleshooting Common Issues
- Conclusion: Unlocking the Power of Spark SQL